This is a guide for developers seeking to give ChatGPT the ability to query a SQL database using a GPT Action. Before reading this guide, please familiarize yourself with the following content:
This guide outlines the workflow required to connect ChatGPT to a SQL Database via a middleware application. We’ll use a PostgreSQL database for this example, but the process should be similar for all SQL databases (MySQL, MS SQL Server, Amazon Aurora, SQL Server on Google Cloud, etc.). This documentation outlines the steps required to create GPT Action which can:
Given that most managed SQL databases do not provide REST APIs for submitting queries, you will need a middleware application to perform the following functions:
Accept database queries via REST API requests
Forward queries to the integrated SQL database
Convert database responses in to CSV files
Return CSV files to the requestor
There are two main approaches to designing the first function:
The middleware supports a single method for receiving arbitrary SQL queries generated by the GPT and forwards them to the database. The benefits of this approach include:
Ease of development
Flexibility (doesn’t require you to anticipate the types of queries users will make)
Low maintenance (doesn’t require you to update the API schema in response to database changes)
The middleware supports a number of methods corresponding to specific allowed queries. The benefits of this approach include:
4. More control
5. Less opportunity for model error when generating SQL
This guide will focus on option 1. For those interested in option 2, consider implementing a service like PostgREST or Hasura to streamline the process.
Developers can either build custom middleware (commonly deployed as serverless functions with CSPs like AWS, GCP, or MS Azure) or use third-party solutions (like Mulesoft Anypoint or Retool Workflows). Using third-party middleware can accelerate your development process, but is less flexible than building it yourself.
Building your own middleware gives you more control over the application’s behavior. For an example of custom middleware, see our Azure Functions cookbook.
Rather than focusing on the specifics of middleware setup, this guide will focus on the middleware’s interface with the GPT and SQL database.
GPTs are very good at writing SQL queries based on a user’s natural language prompt. You can improve the GPT’s query generation capabilities by giving it access to the database schema in one of the following ways:
Instruct the GPT to start by querying the database to retrieve the schema (this approach is demonstrated in more detail in our BigQuery cookbook).
Provide the schema in the GPT instructions (works best for small, static schemata)
Here are sample GPT instructions which include information about a simple database schema:
# ContextYou are a data analyst. Your job is to assist users with their business questions by analyzing the data contained in a PostgreSQL database.## Database Schema### Accounts Table**Description:** Stores information about business accounts.| Column Name | Data Type | Constraints | Description ||--------------|----------------|------------------------------------|-----------------------------------------|| account_id |INT|PRIMARYKEY, AUTO_INCREMENT, NOTNULL| Unique identifier for each account || account_name | VARCHAR(255) |NOTNULL| Name of the business account || industry | VARCHAR(255) || Industry to which the business belongs || created_at |TIMESTAMP|NOTNULL, DEFAULTCURRENT_TIMESTAMP| Timestamp when the account was created |### Users Table**Description:** Stores information about users associated with the accounts.| Column Name | Data Type | Constraints | Description ||--------------|----------------|------------------------------------|-----------------------------------------|| user_id |INT|PRIMARYKEY, AUTO_INCREMENT, NOTNULL| Unique identifier for each user || account_id |INT|NOTNULL, FOREIGN KEY (References Accounts(account_id)) | Foreign key referencing Accounts(account_id) || username | VARCHAR(50) |NOTNULL, UNIQUE| Username chosen by the user || email | VARCHAR(100) |NOTNULL, UNIQUE| User's email address || role | VARCHAR(50) || Role of the user within the account || created_at |TIMESTAMP|NOTNULL, DEFAULTCURRENT_TIMESTAMP| Timestamp when the user was created |### Revenue Table**Description:** Stores revenue data related to the accounts.| Column Name | Data Type | Constraints | Description ||--------------|----------------|------------------------------------|-----------------------------------------|| revenue_id |INT|PRIMARYKEY, AUTO_INCREMENT, NOTNULL| Unique identifier for each revenue record || account_id |INT|NOTNULL, FOREIGN KEY (References Accounts(account_id)) | Foreign key referencing Accounts(account_id) || amount | DECIMAL(10, 2) |NOTNULL| Revenue amount || revenue_date |DATE|NOTNULL| Date when the revenue was recorded |# Instructions:1. When the user asks a question, consider what data you would need to answer the question and confirm that the data should be available by consulting the database schema.2. Write a PostgreSQL-compatible query and submit it using the `databaseQuery`API method.3. Use the response data to answer the user's question.4. If necessary, use code interpreter to perform additional analysis on the data until you are able to answer the user's question.
In order for our GPT to communicate with our middleware, we’ll configure a GPT Action. The middleware needs to present a REST API endpoint which accepts a SQL query string. You can design this interface in several ways. Here is an example of an OpenAPI schema for a simple endpoint which accepts a “q” parameter in a POST operation:
openapi: 3.1.0info: title: PostgreSQL API description: APIfor querying a PostgreSQL database version: 1.0.0servers:- url: https://my.middleware.com/v1 description: middleware servicepaths:/api/query: post: operationId: databaseQuery summary: Query a PostgreSQL database requestBody: required: true content: application/json: schema:type: object properties: q:type: string example: select *from users responses:"200": description: database records content: application/json: schema:type: object properties: openaiFileResponse:type: array items:type: object properties: name:type: string description: The name of the file. mime_type:type: string description: The MIMEtype of the file. content:type: stringformat: byte description: The content of the filein base64 encoding."400": description: Bad Request. Invalid input."401": description: Unauthorized. Invalid or missing API key. security:- ApiKey: []components: securitySchemes: ApiKey:type: apiKeyin: header name: X-Api-Key schemas: {}
A note on authentication: The API interface in the above example accepts a single system-level API key which is stored along with the GPT’s configuration and used to authenticate requests for all GPT users. GPT Actions also support OAuth authentication, which enables user-level authentication and authorization. Learn more about GPT Action authentication options.
Because the user is authenticating with middleware and not directly with the underlying database, enforcing user-level access (table or row-level permissions) requires more effort. However, it may be required for GPTs where users have different levels of access to the underlying database.
In order to enforce user-level permissions, your middleware should:
Receive the user’s metadata provided by the IdP during the OAuth flow and extract their identifying information
Query the database to retrieve the user’s database permissions
Issue a command to the database to enforce the relevant permissions for the remainder of the session
In order to maintain a good user experience, you’ll want to dynamically retrieve the available database schema for each user as opposed to including the schema data in the GPT instructions directly. This ensures that the GPT only has access to tables which it can query on behalf of the current user.
Your middleware will implement a database driver or client library to enable it to query the PostgreSQL database directly. If you are using third-party middleware, the middleware vendor should provide native connectors for SQL databases. If you are building your own middleware, you may need to implement a client library provided by the database vendor or a third-party. For example, here is a list of community-maintained client libraries for PostgreSQL: https://wiki.postgresql.org/wiki/List_of_drivers
During this workflow step, the middleware application needs to extract the SQL string from the request it received from the GPT and forward it to the database using the methods provided by the client library.
A note on read-only permissions: Given that this design pattern results in your database processing arbitrary AI-generated SQL queries, you should ensure that the middleware application has read-only permissions on the database. This ensures that the AI-generated queries cannot insert new data or modify existing data. If write access is required for your use-case, consider deploying operation-specific endpoints rather than accepting arbitrary SQL.
Depending on the client library you have implemented, your middleware may receive records in a variety of formats. One common pattern is for your middleware to receive an array of JSON objects, each object representing a database record matching the query:
In order for ChatGPT to analyze large numbers of records, it needs access to data in a CSV format. The GPT Actions interface allows GPTs to receive base64-encoded files of up to 10mb in size.
Many programming languages include a native library for working with CSV files (the Python csv library, for example).
Here’s an example of how your middleware could convert an array of JSON objects into a CSV file:
import jsonimport csv# Sample JSON array of objectsjson_data ='''[ {"account_id": 1, "number_of_users": 10, "total_revenue": 43803.96, "revenue_per_user": 4380.40}, {"account_id": 2, "number_of_users": 12, "total_revenue": 77814.84, "revenue_per_user": 6484.57}]'''# Load JSON datadata = json.loads(json_data)# Define the CSV file namecsv_file ='output.csv'# Write JSON data to CSVwithopen(csv_file, 'w', newline='') as csvfile:# Create a CSV writer object csvwriter = csv.writer(csvfile)# Write the header (keys of the first dictionary) header = data[0].keys() csvwriter.writerow(header)# Write the data rowsfor row in data: csvwriter.writerow(row.values())print(f"JSON data has been written to {csv_file}")
In order for the GPT Actions interface to process the base-64 encoded CSV file, the response returned by your middleware must contain an openaiFileResponse parameter. The value provided must be an array of file objects or links to files (see the Actions documentation for more details). For the purposes of this example, we will work with an array of file objects.
Here is an example of what a valid response body looks like:
Once your GPT receives the base64-encoded CSV file, it will automatically decode the file and process it to answer the user’s question. This may involve using code interpreter to perform additional analysis against the CSV file, which happens the same way as if a user had uploaded the CSV file via the prompt.
Note: You must enable the Code Interpreter & Data Analysis capability in your GPT if you want to be able to perform additional analysis on the returned file.
GPT Actions provide a flexible framework for retrieving data from external sources like SQL databases. Giving ChatGPT the ability to query a database can substantially expand its capabilities as a knowledge assistant and analyst.
Are there integrations that you’d like us to prioritize? Are there errors in our integrations? File a PR or issue in our github, and we’ll take a look.
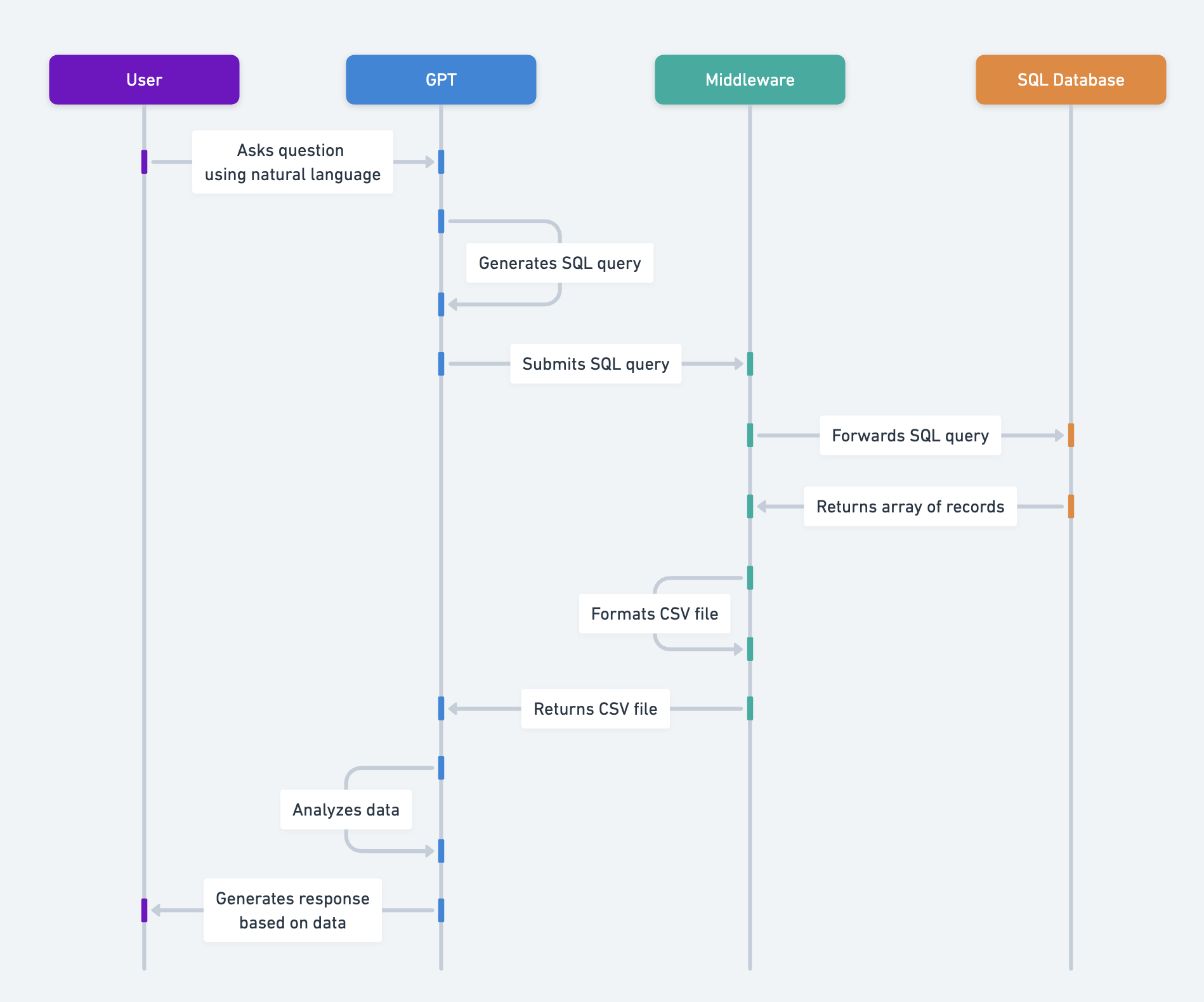 Application architecture diagram
Application architecture diagram